Federal Contracting and IT Certifications Listing
General & Misc:
- ARM – Associate in Risk Management, Insurance Institute of America
- CCS – Certified Coding Specialist, AHIMA (American Health Information Management Association)
- CDFM – Certified Defense Financial Manager, ASMC (American Society of Military Comptrollers)
- CFA – Chartered Financial Analyst, CFA Institute
- CFE – Certified Fraud Examiner, ACFE (Association of Certified Fraud Examiners)
- CGFM – Certified Government Financial Manager, AGA (Association of Government Accountants)
- CGMA – Chartered Global Management Accountant, AICPA (American Institute of Certified Public Accountants) & CIMA (Chartered Institute of Management Accountants)
- CGOVP – Certified Corporate Governance Professional, The GRC Group
- CGRCP – Certified Governance Risk Compliance Professional, The GRC Group
- CHC – Certified in Healthcare Compliance, CCB (Compliance Certification Board)
- CHFP – Certified Healthcare Financial Professional, HFMA (Healthcare Financial Management Association)
- CISSP – Certified Information Systems Security Professional, (ISC)²
- CIRA – Certified Insolvency and Restructuring Advisor, AIRA (Association of Insolvency & Restructuring Advisors)
- CMA – Certified Management Accountant, IMA (Institute of Management Accountants)
- CSCA – Certified in Strategy and Competitive Analysis, IMA (Institute of Management Accountants)
- CPCM / CFCM / CCCM – Certified Professional/Federal/Commercial Contract Manager, NCMA (National Contract Management Association)
- CPSM – Certified Professional in Supply Management, ISM (Institute for Supply Management)
- CRMA – Certified Risk Management Assurance, IIA (Institute of Internal Auditors) – this now includes the soon-to-be-obsolete CCSA (Certification in Control Self-Assessment)
- CSOXP – Certified Sarbanes-Oxley Professional, The GRC Group
- CSSLP – Certified Secure Software Lifecycle Professional, (ISC)²
- DAWIA Levels I, II, and III – Defense Acquisition Workforce Improvement Act (DoD Acquisitions), DAU (Defense Acquisition University)
- ERP – Energy Risk Professional, GARP (Global Association of Risk Professionals)
- FAC-C or FAC-COR or FAC-P/PM – Contracting, FAI (Federal Acquisition Institute)
- FRM – Financial Risk Manager, GARP (Global Association of Risk Professionals)
- ITIL – Information Technology Infrastructure Library – Expert Certification
- PMP – Project Management Professional, PMI (Project Management Institute). We would recommend against taking the CAPM (Certified Associate in Project Management), as it is more preferable to skip straight to PMP, once you meet the qualifications.
- Six Sigma Black Belt or Lean Six Sigma Black Belt, Six Sigma
CPA & AICPA-specific:
- CPA – Certified Public Accountant, AICPA (American Institute of Certified Public Accountants)
- ABV – Associate in Business Valuation, AICPA (American Institute of Certified Public Accountants)
- CFF – Certification in Financial Forensics, AICPA (American Institute of Certified Public Accountants)
Audit:
- CFSA – Certified Financial Services Auditor, IIA (Institute of Internal Auditors)
- CGAP – Certified Government Audit Professional, IIA (Institute of Internal Auditors)
- CIA – Certified Internal Auditor, IIA (Institute of Internal Auditors)
- CISA – Certified Information Systems Auditor, ISACA
Information Systems and Security:
- CASP+ – CompTIA Advanced Security Practitioner, CompTIA. CISSP is more well-known and prestigious.
- CISM – Certified Information Security Manager, ISACA. Note: CISSP is the more technical and difficult version of the more management-focused (higher level risk management) CISM, so CISSP is more highly recommended prestigious cert.
- CRISC – Certified in Risk and Information Systems Control, ISACA
- CySA+ – Cybersecurity Analyst, CompTIA
- GSEC – GIAC Security Essentials, GIAC (Global Information Assurance Certification) THEN next level GCED – GIAC Certified Enterprise Defender, GIAC (Global Information Assurance Certification)
- Security+, CompTIA
Agile & Scrum:
- CSM – Certified ScrumMaster, Scrum Alliance
- PSM (Levels I, II & III) – Professional Scrum Master, Scrum.org. Note: There isn’t consensus of which certification is preferable, however, CSM is more well-known in North America and consists of an expensive $1200 2-day class, while PSMs consist only of (more difficult) exams that one self-studies for and is more affordable ($150 per exam). PSM is more well-known in Europe.
- SAFe – Scaled Agile Framework (various certifications), Scaled Agile, Inc.
- LeSS – Certified LeSS (Large-Scale Scrum) Practitioner, The LeSS Company B.V. More well-known in Europe, while SAFe is more well known in North America.
Cloud:
- AWS Certified Solutions Architect – Associate, AWS Certified Developer – Associate, or AWS Certified SysOps Administrator – Associate, AWS (Amazon Web Services)
- Azure Solutions Architect Expert or Azure Developer Associate, Microsoft Azure
- GCP Associate Cloud Engineer, then GCP Professional Cloud Architect, GCP (Google Cloud Platform)
- CCSP – Certified Cloud Security Professional, (ISC)²
SysAdmin:
- LPIC-1 – System Administrator, LPIC-2 – Linux Engineer, & LPIC-3 (various), Linux Professional Institute. These are outdated certifications, skip to the Redhat certs below instead of getting these.
- RHCSA – Red Red Hat Certified System Administrator, then RHCE – Red Hat Certified Engineer, Red Hat
- LFCS – Linux Foundation Certified SysAdmin, then LFCE – Linux Foundation Certified Engineer, Linux Foundation. The Redhat certs are more well-known over the Linux Foundation.
- MCSE – Microsoft Certified Solutions Expert (e.g. Core Infrastructure), Microsoft
- CCIE – Cisco Expert Certifications, Cisco
Hacking and Penetration Management:
- CEH – Certified Ethical Hacker Certification, EC-Council
- CPTE – Certified Penetration Testing Engineer, mile2
- CPT – Certified Penetration Tester, IACRB (Information Assurance Certification Review Board)
- OSCP – Offensive Security Certified Professional, Offensive Security
- PenTest+, CompTIA
Networking and related Security:
- CCNA Routing & Switching, Cisco
- Network+, CompTIA
Note: Take any CompTIA exam for cheaper with an EDU email address.
Other Professional Organizations for Membership:
Listing of Tools, Software, Programming Languages, and their Usage and Comparisons
Cloud Hosting: Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform – BigQuery, Snowflake, IBM Cloud Private, HP Cloud
Data Storage (i.e. Transactional or Financials Platform): Hortonworks, Hadoop, Oracle, Microsoft, PostgreSQL
Semantic Tier: LucidWorks, Solr, ElasticResearch
Presentation & Visualization: Tableau, Qlik Sense, Microsoft Power BI
ETL & Analytics: SAS, Revolution, SPSS
- Alteryx – Shines at repetitive and collaborative ETL – data extract, transform (blending) & load), with only a little bit of statistical analysis (predictive analytics, spatial, demographic & behaviors advanced data analytics). For rapidly prototyping a process or to quickly answer a business question, while Python and R are better suited for developing production high demand systems, mathematical and statistical modelling, and utilizing popular algorithms of machine learning and deep learning. Pros – Can deal with larger datasets than R. Data Integration & Management Substitutes to Alteryx: Pentaho, Storm, Informatica, Microsoft SQL Server IS, RapidMiner, KNIME, Hive, Spark
- Python – Python (open source) emphasizes productivity and code readability, and can be used by programmers to delve into data science – analysis or apply statistical techniques. Can take data from external sources and hold it internally within a DataFrame, however can also allow for running of code as part of an Alteryx workflow. Pandas and NumPy have built in functions to work on arrays, with synonymous functions between the two. Python can automate everything, from data gathering to transformation, analysis, modelling, and visualizations. Coding and debugging is easier because of the clean syntax, and code indentation affects its meaning. Limitation – Data may become much larger memory-wise and more processor-intensive in DataFrame.
- R – R (open source) is focused on user friendly data analysis, statistics and graphical models than Python, which is more powerful and can be used for a greater variety of purposes. It has primarily been used in academics and research by beginner programmers, but has been branching into enterprise industries.
- SAS
- SPSS
- Revolution
Programming Languages: Python, Apache Spark, JavaScript, Java, SQL
Machine Learning: Scikit for Python, Pyflux for Python
Deep Learning: Caffe
Neural Networks: Tensor Flow
Communication Tools: Slack, Yammer, Microsoft Teams, Skype for Business
AWS Architectural Pieces and Capability Functions
- Rest APIs – having APIs in between the user and the endpoint allows for security features, throttling, monitoring and stage deployment so it is good edge protection
- Lambda and Step Functions – A Lambda is a compute service that lets you run code without provisioning or managing servers – such as pick up data from APIs, prepare data, and allows aggregation of calls. A Step Function is a server-less coordinator of multiple Lambda functions into flexible workflows that are easy to debug and change.
- SNS – simple notification service, topic-based (publisher/subscriber), messages are pushed to receivers and processed in different ways. Kinesis Streams is an alternative to SNS/SQS but not as simple to use and less scalable.
- SQS – simple queue service, queue-based, receivers pull messages from SQS and messages are identical, mainly used to decouple applications or integrate applications, messages can be stored for a short duration – max 14 days, allows for batches while SNS does not. SQS+SNS is almost always a better solution than Kinesis, which only has the benefits of granting ability to (1) read the same message from several applications and (2) re-read messages, both of which can be can be achieved by using SNS as a fan out to SQS.
- VPC (Virtual Private Cloud) – Similar to a VPN, loading applications on AWS Cloud servers.
- CI/CD Pipeline – automates software delivery. In CI (continuous integration), the new build is neither automatically deployed in test servers for UAT nor deployed in production after UAT (user acceptance testing), while in CD (continuous delivery) it is automatically delivered for UAT but not deployed in production after UAT. AWS CodePipeline is a managed CD service, with a pipeline consisting of stages each with many actions. The first two stages of a CD pipeline (build and test) are generally a trigger of actions to a Jenkins Job (the most popular open-source CI server with CD capabilities) or AWS CodeBuild service (another un-managed CI system), then an AWS CodeDeploy service.
- Elastic Beanstalk and OpsWorks are packaged environments, bundling in auto scaling, load balancing, ec2 instances, application-level monitoring, and a few other options. CodeDeploy deploys to existing resources, while the formers are more end-to-end software management systems.
- CloudFormation – Provides a common language to describe and provision all the infrastructure resources in your cloud environment. Allows for the automation of setting up of stacks (Stack Pools)
- EC2 – elastic cloud compute, popular for hosting websites or Web apps. AWS Batch enables developers, scientists, and engineers to easily and efficiently run hundreds of thousands of batch computing jobs, and could also use spot instances (temporary usage) for 90% off normal EC2 pricing. Managing EC2 endpoints allows for deployment without interruption of service and A/B spreading of the load – 10% of traffic on new model and 90% of traffic on old model and switch over completely once confident. As a slightly more expensive alternative, AWS EMR (Elastic MapReduce) is a collection of EC2 instances with Apache Hadoop (and optionally Apache Hive and/or Pig) installed and configured on them, allowing for better scalability.
- S3 – Simple storage service (5TB limit) for objects, not blocks. Can host the static data that the website or Web app serves (images, files) or back up EC2 data or store data that EC2s share. Stores files in a flat organisation of containers called Buckets. S3 uses unique Ids called Keys to retrieve files from the bucket. Each object has a url which can be used to download it, or it can be delivered via Amazon Cloudfront CDN (Content Delivery network), or archived to the Amazon Glacier archival service. No query/search/indexes. Can replace but not update files. Versioning or listing cost money.
- DynamoDB (DDB)- NoSQL database which is built for storing a large number of small records (400KB limit) with single digit millisecond latency. Not a relational database. DynamoDb is used to store key-value. It uses items and attributes for its tables. Each item contains different number of attributes. DynamoDb supports two kinds of primary keys, Partition Key and Partition key and Sort key. Similar to MongoDB and Apache Cassandra.
- AWS RDS (Relational Database Management Systems) – e.g. AWS Aurora, or available for Oracle, PostgreSQL, MySQL, MariaDB, Microsoft SQL Server, etc. Effective OLTP (Online Transactional Processing) for front-end frequent reads and writes.
- AWS Redshift and Athena – Redshift allows for querying and transforming of data, with the function of Redshift Spectrum allowing querying of data that exists directly on S3. Athena also queries and analyzes data directly in S3, but is more cost-effective and good for ad-hoc (serverless and integrated with AWS Glue), while Redshift is stronger at performance and for scale. These are more for OLAP (Online Analytic Processing) – aggregate calculations as opposed to the frequent “reads” of OLTP. EMR is a cluster platform better for unstructured data frameworks like Hadoop and Spark, but is more technical and for Big Data analytics & BI, can transform and move large amounts of data in and out of databases (DynamoDB) and other data storage (S3). Redshift is better for structured data (e.g. a CSV file).
- AWS Glue – An ETL service.
- Docker – Can be called with AWS ECS (Elastic Container Service) to easily run and scale containerized applications. ECS can launch with AWS Fargate or EC2 (gives you more control).
- Kubernetes – The more advanced version of Docker. Manage clusters of compute instances and scheduling containers based on required and available resources. Could deploy on either its own EC2 (to be in full control of instance management), EKS (Elastic Container Service for Kubernetes – don’t need to run master instances, easily deploy manage and scale – can integrate in other cloud services or on-prem but costs money), or ECR (Elastic Container Registry – free but can only use within AWS).
- SageMaker – data science team can use this to build predictive models
- CloudWatch – Default logging service – monitors performance and accuracy and develops metrics, such as of SageMaker models. Can also set automation rules e.g. alarms.
- CloudTrail – Only for auditing changes to services (event history logs). Only for API calls, security.
- IAM – centralized identity and access management
- Quicksight – A visualization dashboard tool (Business Intelligence Solution) similar to Tableau.
- Cost and Usage Report – Estimates charges related to your AWS account.
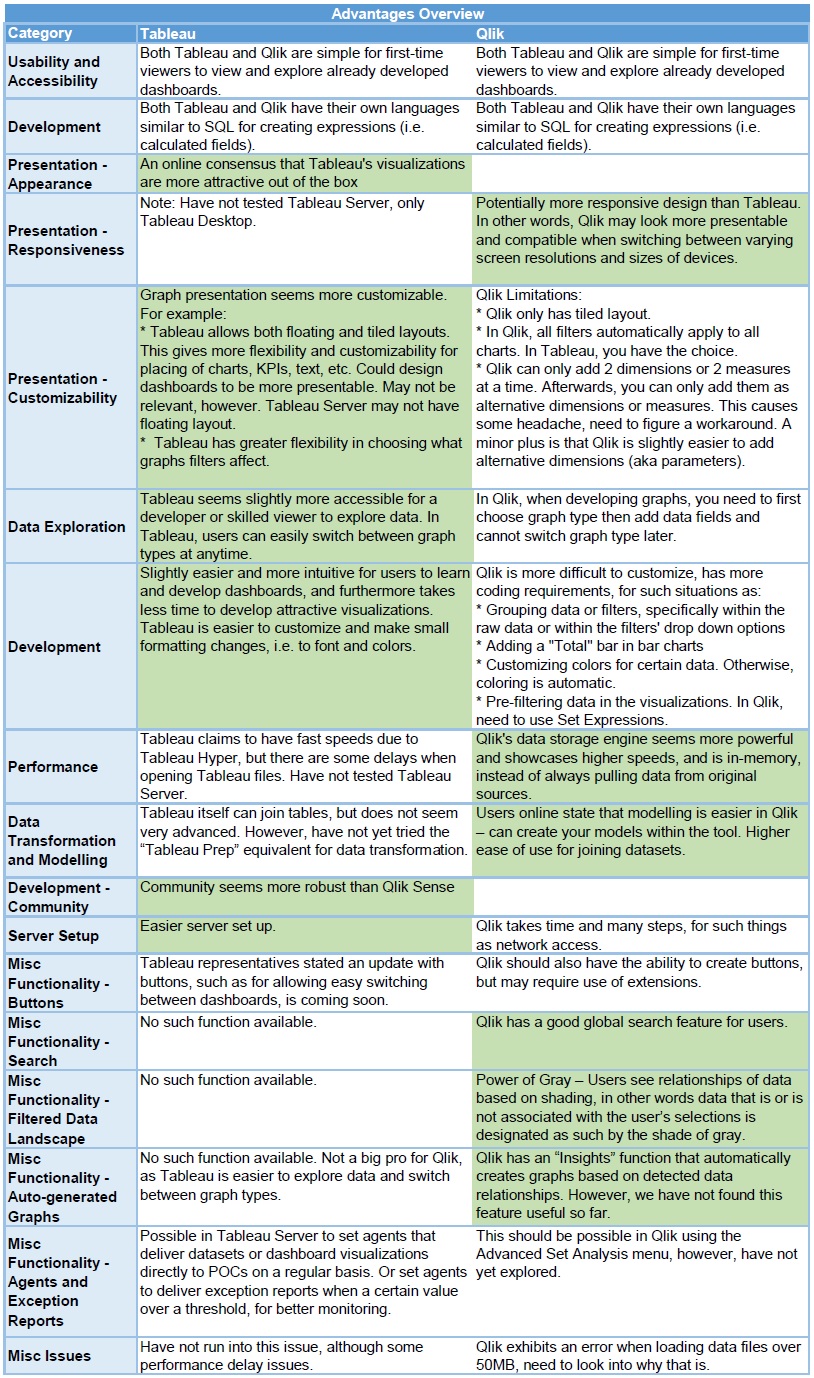
Tableau vs Qlik Sense Comparison